Repenser son style de codage
du code, pour qui, pourquoi ?

Cela fait des années que je place différemment mes accolades { }, à contre-courant de ce qui se fait généralement en Java, faisant ainsi ressembler mon code à du C/C++. Ce billet est l’occasion de faire une sorte d’introspection sur ma pratique : Est-elle bonne ? Est-elle désuète ? Pourquoi je n’aime pas le style SUN ? Est-ce que mon style est utile ou inutile ?
Que de questions auxquelles ce billet va tenter de répondre.
TL;DR
Aujourd’hui pas de “Too Long, Did not read”, ce sujet mérite des explications. Il n’y a donc pas un truc à récupérer tout fait dans GitHub. Désolé, il vous faudra lire toute cette page.
Allez, courage !

C’est parti …
Java est-il verbeux ?
Java est verbeux, oui, c’est vrai. Point final.
Bon, je vais argumenter un peu quand même …
Au lieu de trouver que cela est un défaut comme un grand nombre de personne le pense, j’estime à l’inverse que c’est une force : des packages, des classes, des méthodes et des variables bien nommés éviteront à 95% d’avoir besoin de le commenter.
En effet, il suffira de lire le code, suffisamment expressif par lui-même, pour comprendre aisément ce qu’il fait.
Le mot “code” d’ailleurs, est étrange non ? Un développeur “code”. Pour qui ? Pour la machine ? Oui et Non !
Récemment, je n’ai jamais vu un développeur coder directement en binaire et pourtant c’est ce que va comprendre la machine.
En général, un développeur va utiliser un langage qui peut sembler être difficile à lire pour certain, mais c’est bien une langue intermédiaire entre le langage naturel de tous les jours et le langage machine exprimé en binaire. D’ailleurs c’est pour cela que nous avons besoin de traducteurs : les fameux compilateurs ou interpréteurs ou équivalent.
Quand je parle de “code” à quelqu’un qui n’est pas de la profession, il pense que je fais de l’hexadécimal façon Matrix toute la journée. C’est un “code”, c’est un “truc” illisible par définition.

Cependant le code (le programme), doit être lisible, compréhensible et maintenable par d’autres personnes. C’est pour cela que nous avons un langage commun, dans notre cas il s’agit de Java, mais cela vaut pour tous les langages.
Voilà pourquoi Java est verbeux, et c’est une bonne chose ! Un développeur écrit un programme qui passera par de nombreuses moulinettes, statiques ou dynamiques, afin d’être exécutable et exécuté. Mais il écrit aussi et surtout pour lui-même et pour les autres. C’est par ailleurs l’une des raisons pour lesquelles je ne comprendrai jamais le fameux “Quick & Dirty”.
Attention, quand je dis verbeux, il faut toutefois faire attention à ce que l’on fait. Récemment je suis tombé sur ce Slide dans cette Présentation :
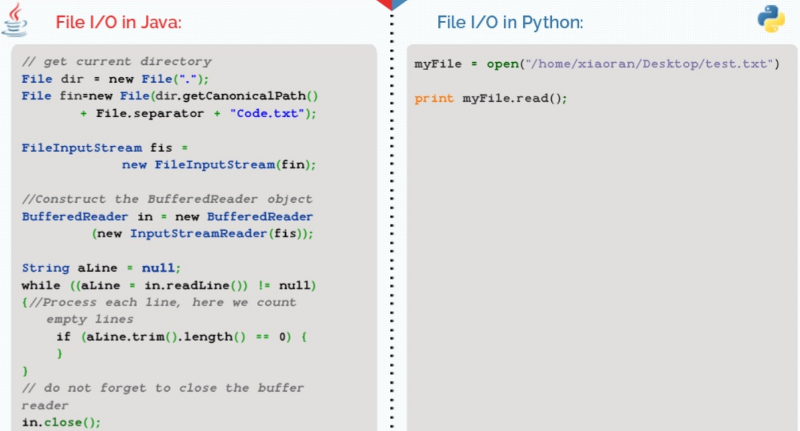
Ce n’est pas très flatteur pour Java. Ce qui est mis en cause ici est la conception des API I/O assez complexe ainsi que sa fameuse verbosité …
On excusera l’auteur de ce Slide, en novembre 2013, Java 8 n’était qu’en “early access” puisqu’il est sorti en janvier 2014, mais avec cette version on peut remplacer tout le code Java ci-dessus par celui-ci :
Files.lines(Paths.get("fichier.txt")).forEach(System.out::println);
Pour le coup, cette ligne de code est succincte, mais verbeuse (oui !) et donc expressive.
Le postulat admis “Java c’est verbeux” est-il suffisant pour que cela en fasse du code lisible, compréhensible et maintenable ?
Du code lisible, j’en fais comment ?
Avant de vous montrer ce que je pense être du code lisible, je vais commencer par ce que j’estime être illisible et pourquoi.
Extrait de Java HashMap
Source complet ici : http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/share/classes/java/util/HashMap.java :
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Wouah ! Je vais chercher un masque, des palmes et je reviens …

Alors “Qu’est-ce qu’on a ? Docteur ?” :
- quatre
ifimbriqués - edit : ah non trois (ça commence bien)
- merci la colorisation syntaxique qui m’aide un peu à m’y retrouver
- une boucle
whileavec un return dedans en cas deifen succès - toutes les variables, pourtant de différents types, déclarées sur une seule ligne : on dirait qu’un minifier est passé par là
- un commentaire de dingue en début de méthode : “Implements Map.get and related methods”. C’est très clair … que c’est pas clair.
Et puis surtout : cette indentation qui me fait perdre la tête.

Si j’osais, je dirais que ce code a été fait exprès ainsi pas pour ne pas être maintenable par une tièrce personne. Et pour parachever le tout, ce code ne respecte pas non plus les conventions de codage SUN/Oracle, c’est un comble.
Je vais maintenant le restructurer à ma façon au moyen d’accolades { ... }, sans changer pour autant l’algorithme ni découper le code pour le rendre plus compréhensible. Cet aspect sera traité plus loin dans cet article.
L’idée est simplement de structurer sa représentation différement afin d’identifier les portions rapidement et donc de le rendre plus lisible.
Attention, les conventions classiques “Java” vont prendre un sacré coup, vous êtes avertis. Je vais même un peu exagérer, histoire de vous faire réagir (ou pas)
final Node<K,V> getNode
(int hash,
Object key)
{
Node<K,V>[] tab;
Node<K,V> first, e;
int n;
K k;
if ((tab = table) != null
&& (n = tab.length) > 0
&& (first = tab[(n - 1) & hash]) != null)
{
if (first.hash == hash
&& ((k = first.key) == key || (key != null && key.equals(k))))
{
return first;
}
else if ((e = first.next) != null)
{
if (first instanceof TreeNode)
{
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
}
else
{
do
{
if (e.hash == hash
&& ((k = e.key) == key || (key != null && key.equals(k))))
{
return e;
}
} while ((e = e.next) != null);
}
}
}
return null;
}
Alors oui d’accord, c’est moins compact visuellement. C’est justement le but : montrer la complexité d’un code quand il l’est. C’est un peu subjectif, mais on obtient ainsi du code plus lisible. Je vais toutefois argumenter un peu pour vous en convaincre.
Quand on code une méthode, c’est à dire la créer, la comprendre et la maintenir, il faut identifier rapidement les “zones”. Ces zones, en Java, sont des regroupements, soit exprimés par des { ... } soit par des ( ... ). Pour être efficace, il faut donc pouvoir :
- visualiser rapidement son nom et ce qu’elle retourne
- visualiser d’un seul tenant tous les arguments, leur nombre et leur type : mon oeil préfère compter des sauts de ligne que des virgules.
- identifier rapidement les portions de code
{ ... } - donner du sens. Le code initial comportait implicitement deux
elseet pourtant ces clauses n’étaient pas visibles. Maintenant elles le sont, rendant certainement le code plus compréhensible. - les conditions dans les
ifavec des pré-affectations dans des variables, je préfère les voir sur plusieurs lignes. Je vois ainsi rapidement les clauses restrictives&&. Les clauses||en revanche je les ai laissées sur la même ligne, donnant une sorte de “soit/soit” qu’on retrouve d’ailleurs dans la syntaxe de l’opérateur ternaire[condition] ? [true] : [false]. - tous les
ifmême s’ils n’avaient qu’une seule ligne de code à déclencher en cas de succès, se retrouvent équipés d’un bloc{ .. }. Cela évitera les erreurs de maintenance, quand un autre développeur voudra rajouter une ligne, qui curieusement ne se lancera pas … Cette règle est d’ailleurs présente dans de nombreuses conventions et bonnes pratiques.
L’ensemble de ces petites mesures rendent donc le code plus lisible, mais pas nécessairement plus compréhensible encore.
Structure visuelle
En m’inspirant d’une présentation de Kevlin Henney (voir en conclusion), on peut même en faire des blocs et comprendre ainsi les imbrications et les différents cas.
Vous serez supris de voir que vous serez en mesure d’identifier les arguments, les variables, les conditions et les boucles de cet algorithme, d’un seul coup d’oeil :
XXXXX XXXXXXXXX XXXXXXX
/XX XXXXX
XXXXX XXX/
|
XXXXXXXXXXX XXXX
XXXXXXXXX XXXXXX
XXX XX
X XX
XX /$$$$$$$$$$$$$$$$$$$$$$$
XX $$$$$$$$$$$$$$$$$$$$$
XX $$$$$$$$$$$$$$$$$$$$$$$$$$$$$ XX $$$$$/
|
XX /$$$$$$$$$$$$$$$
XX $$$$$$$$$$$$$$$$$$$$$$$ XX $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$/
|
XXXXXX $$$$$$
|
XXXX $$$$$$$$$$$$$$$$$$$$$$$$$$$$
|
XX /$$$$$$$$$$$$$$$$$$$$$$$$$$/
|
XXXXXX $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
|
XXXX
|
XX
|
XX /$$$$$$$$$$$$$$
XX $$$$$$$$$$$$$$$$$$$ XX $$$$$$$$$$$$$$$$$$$$$$$$$/
|
XXXXXX $
|
| XXXXX $$$$$$$$$$$$$$$$
|
|
|
XXXXXX $$$$;
|
Etonnant non ? N’arrivez-vous pas à voir la structure de cette méthode ?
Et pourtant j’ai tout enlevé pour ne laisser que l’indentation, les retours à la ligne et seulement quatre caractères X $ | /.
En effet, notre cerveau accorde beaucoup d’attention à la représentation spatiale des choses, à la leur forme, leur couleur. La structure d’un programme n’échappe pas à cette caractéristique, c’est pour cela qu’on aime avoir de la colorisation syntaxique dans nos IDE.
Si une voiture avait la forme d’une pomme vous penseriez d’abord à la manger avant de la conduire. C’est après une seconde analyse, certes rapide, que votre cerveau déduit que la pomme est trop grosse et qu’elle circule sur la route … c’est une voiture. Mais quel effort pour pas grand chose : DONNEZ DE LA FORME A VOTRE CODE, votre cerveau vous remerciera !
Pour tenter de vous en convaincre, voici le même code source, sans colorisation, sans indentation :
final Node<K,V> getNode (int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null)
{ if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
} } }
C’est rude, non ? Et pourtant il s’agit du même code !
Maintenant que la structure de l’algorithme est plus lisible, dans sa version Java, bien sûr, il va falloir le rendre plus compréhensible. C’est ce que l’on va faire dans les parties suivantes.
Mais il fait quoi ce code ?
Alors, en examinant à la loupe l’implémentation de la méthode getNode(), voici ce que l’on peut en comprendre :

- elle vérifie des préconditions, sinon elle retourne
null. - elle prend le premier élément d’une liste chainée et le retourne si c’est lui. Cet élément est atteint au moyen d’un index en fonction du hash de la clé de l’élement. C’est peut-être le point le plus délicat de l’algo.
- elle vérifie ensuite si le
Nodeest de typeTreeNode, si c’est le cas elle délègue la recherche à une autre méthode. - sinon elle parcourt la liste chainée pour retourner l’élement voulu quand elle le trouve.
- sinon elle retourne
null.
Donc, on va refactoriser tout cela pour le rendre plus compréhensible, tout en restant lisible, je l’espère.
Goldorak ! REFACTORISATION !

Malheureusement, Goldorak ne connait pas cet ordre d’Actarus. Il va donc falloir le faire nous même, même si nos IDE préférés peuvent nous y aider.
Après un peu de réflexion, TADAAAAA :
final Node<K,V> getNode
(int keyHash,
Object key)
{
if (!checkTablePreConditions())
{
return null;
}
else
{
Node <K,V> firstNode = getFirstNode();
if (matchesOrNull(keyHash, key, firstNode))
{
return firstNode;
}
else if (hasNext(firstNode))
{
return search(keyHash, key, firstNode);
}
}
}
Believe it or not, cet algorithme est le reflet exact de la méthode initiale qui a simplement été décomposée.
Si vous vous inquiétez des performances liées aux appels de sous-méthodes, sachez que le JIT (just-in time compiler) et notamment sa fonction de “method inlining” fera toujours mieux que toutes les pseudos-optimisations que l’on pourra imaginer. Si vous voulez un peu d’information vulgarisée à ce sujet je vous recommande cet article.
De fait, il est maintenant compréhensible, enfin je crois.
Si vous le comprenez, vous savez maintenant comment fonctionne un get sur une HashMap !
Décomposition en méthodes privées
Je me suis donc équipé en méthodes privées. D’ailleurs il y avait de la redondance de code dans l’algorithme initial … Il est même probable que ces méthodes privées puissent servir dans d’autres méthodes déjà existantes. Réduisant ainsi le coût de maintenance de cette classe !
Préconditions
D’abord, de quoi vérifier les préconditions en entrée sur une variable d’instance nommée table.
private boolean checkTablePreConditions()
{
return (table != null && table.length > 0);
}
Egalité du hash de la clé
Ensuite, de quoi savoir si le Node est celui que l’on cherche, d’abord via le hash de sa clé puis par l’égalité complète de la clé. Dans cette méthode, j’ai inversé le test equals pour économiser un test de nullité par rapport à la version initiale.
private boolean matchesOrNull
(int keyHash,
Object key,
Node<K,V> node)
{
return (node == null || (node.hash == keyHash
&& (node.key == key || (node.key.equals(key)))));
}
Parcours de liste chainée
Deux méthodes, inspirées de l’API Collections et Iterable pour parcourir facilement la liste chainée de Node :
private Node<K,V> hasNext
(Node<K,V> node)
{
return node.next != null;
}
private Node<K,V> next
(Node<K,V> node)
{
return node.next;
}
Pointage sur la bonne case du tableau
De quoi récupérer le premier Node en fonction du hash de sa clé :
private Node<K,V> getFirstNode
()
{
return table[(table.length - 1) & hash];
}
Parcours et recherches
Et enfin de quoi parcourir les structures :
- dans le premier cas, comme dans l’algorithme initial, on délègue à une méthode
getTreeNode()dont l’implémentation ici n’est pas le sujet. - dans le second cas, on parcourt la liste chainée jusqu’à trouver le node.
private Node <K,V> search
(int hash,
Object key,
Node<K,V> node)
{
if (node instanceof TreeNode)
{
return ((TreeNode<K,V>)node).getTreeNode(hash, key);
}
else
{
return linkedSearch(hash, key, node);
}
}
private Node <K,V> linkedSearch
(int hash,
Object key,
Node<K,V> node)
{
Node <K,V> currentNode = node;
while(hasNext(currentNode))
{
currentNode = next(currentNode);
if (matches(hash, key, currentNode, node))
{
return currentNode;
}
}
return null;
}
Résumé de la refactorisation
Dans la refactorisation ci-dessus, je n’ai fait que divide ut regnes (diviser pour régner) : rien de magique.
- Il n’y plus de variables bizarres.
- Chaque méthode fait une chose simple, que je pourrais tester facilement avec JUnit.
- J’ai remplacé le
do { ... } whileenwhileclassique, car je préfère ce pattern. - J’ai redonné du sens aux arguments et aux variables.
- Le nommage des méthodes
privateest suffisament explicite. - Le code source de l’algorithme principal devient donc plus lisible, plus compréhensible et plus maintenable.
Parlons des accolades “Java Style”
Je m’acharne encore sur les accolades, mais, vous l’aurez compris, je n’aime pas ce style :
for(Object o : data) {
doSomething(o);
}
ou encore :
public static void main(String... args) {
SpringApplication.run(Application.class, args);
}
Appliquée à la méthode refactorisée, cela donne ceci que bon nombre d’entre-vous préférera sûrement :
final Node<K, V> getNode(int keyHash, Object key) {
if (!checkTablePreConditions()) {
return null;
} else {
Node<K, V> firstNode = getFirstNode();
if (matchesOrNull(keyHash, key, firstNode)) {
return firstNode;
} else if (hasNext(firstNode)) {
return search(keyHash, key, firstNode);
}
}
}
Ce qui me gène ici, ce que l’on fait porter à l’indentation uniquement l’information visuelle de “bloc”, alors que cette information est dévolue normalement aux accolades.
Cela développe en moi une forme de strabisme. J’aime bien voir en ligne et en colonne, mais pas en diagonale.

Cette problématique fait d’ailleurs l’objet d’un paragraphe entier sur Wikipedia : Losing track of blocks. Visiblement, je ne suis pas le seul, c’est rassurant.
Mais alors pourquoi ont-ils fait cela chez SUN ?
Retour en 1997 : Java est sorti depuis presque 2 ans, et internet commence à s’étendre, notamment chez les particuliers.
Il faut que Java se distingue absolument de C et C++ pour ne pas confondre les codes sources que l’on peut trouver sur le net.
SUN sort alors ses conventions codage, pratiquées par l’équipe “Java” depuis 1995 : https://www.oracle.com/technetwork/java/codeconventions-150003.pdf
Voilà comment cette caractéristique visuelle, pour être différenciant de C/C++, se retrouve 20 ans plus tard comme une chose acquise. Oracle publie d’ailleurs toujours ces conventions mais, curieusement, ne les applique pas partout.
Vous vous souvenez de ce que j’ai écrit un peu plus haut sur le “cerveau / les formes” ? Et bien oui, c’est bien cela qui était exploité à l’époque pour identifier d’un seul coup d’oeil, grâce à des conventions, qu’il s’agissait de Java et non pas de C/C++.
Autres styles de codage
Mon style de codage est une sorte d’adaptation entre différents styles connus et célèbres et notamment :
- le K&R style (C et C++)
- le pre-ISO C Style
- l’Allman style (BSD)
- le style GNU
- le Horstmann style
- le Gangnam style … ah non pas celui-là

Il est certes non conventionnel en Java mais il ne sort donc pas de nulle part.
De plus, Je ne suis visiblement pas le seul à revoir ces règles, notamment sur le placement des accolades :
- Apache Commons Net : https://commons.apache.org/proper/commons-net/code-standards.html
- Java Ranch : https://javaranch.com/styleLong.jsp#matching_braces
- JBoss Development Process Guide (2005) : https://docs.jboss.org/process-guide/en/html/coding.html
- Petroware : https://petroware.no/javastyle.html
- Steve Yohanan : http://yohanan.org/steve/projects/java-code-conventions/
Je me demande d’ailleurs si je ne vais pas adopter le style PICO “dérivé FX”, c’est à dire la diagonale inverse de Java :
private Node <K,V>
linkedSearch
(int hash, Object key, Node<K,V> node)
{ Node <K,V> currentNode = node;
while (hasNext(currentNode))
{ currentNode = next(currentNode);
if (matches(hash, key, currentNode, node))
{ return currentNode; } }
return null; }
Je blague …
Et je fais comment avec mon IDE ?
De nos jours, nous sommes un peu “fainéants”, mais c’est pour la bonne cause : se concentrer sur l’essentiel.
Ainsi on laisse souvent le soin à nos IDE de formater correctement notre code source.
Bonne nouvelle ! Que ce soit Eclipse IDE, Netbeans ou IntelliJ, chacun de ces IDE est capable de paramétrer son formatage en fonction de préférences.
Comme j’aime le partage, voici mes règles de formattage à importer dans votre workspace Eclipse :
Ensuite, il faudra revoir les règles CheckStyle qui seront associées.
Et mes autres conventions ?
J’ai évoqué ici principalement mes conventions sur le placement des accolades {...} mais j’en ai d’autres aussi :
- aucune interface avec “I” devant : une interface est un concept ! Vous seriez contents de manipuler des
IListouIMaptoute la journée ? - pas de préfixe sur les arguments
pUser, pEmail, pPreviousState: ça ne sert à rien. - pas de préfixe sur les attributs
aName, aAddress, aEmails: non seulement c’est inutile mais c’est en plus trompeur sur le sens. - pas de préfixe sur les variables locales
_tmp, _i, _dateNaissance: inutile aussi !
Toutes ces conventions, pourtant pratiquées par de nombreuses équipes, n’ont de raison d’être que quand les classes font plus de 3000 lignes, avec 100 lignes de code par méthode et 20 attributs. Comme je fais en sorte de ne pas subir de telles classes symptomatiques d’un embonpoint historique, je n’en ai donc pas besoin.
Ma cible :
- 10 classes et/ou interfaces par package,
- 10 attributs par classes,
- 10 méthodes par classes (hormis getters/setters),
- 10 lignes de code par méthode.
Il m’arrive d’y déroger, comme toute règle, mais je vous suggère d’aller regarder le code source du jeu Xenon Reborn pour vous convaincre de la faisabilité sans pour autant sacrifier la lisibilité.
Conclusion
J’espère vous avoir convaincus sur l’ensemble de ces pratiques, au moyen de l’exemple choisi.
Cela demande quelques efforts, mais les outils de refactoring (extract method, etc.) de vos IDE préférés sont excellents pour cela. N’hésitez pas et pensez à ceux qui passent après vous !
Bon allez, comme vous êtes allés jusqu’à la conclusion, j’avoue, je ne fais pas exactement ce que j’ai mis en exemple de code en ce qui concerne les arguments. Voici plutôt ma façon de faire actuelle avec tous les arguments sur la même ligne :
private Node <K,V> linkedSearch(int hash, Object key, Node<K,V> node)
{
Node <K,V> currentNode = node;
while(hasNext(currentNode))
{
currentNode = next(currentNode);
if (matches(hash, key, currentNode, node))
{
return currentNode;
}
}
return null;
}
Enfin, ce qui prime par dessus tout, il faut que votre équipe de développement accepte de nouvelles conventions. Ce ne sera pas toujours le plus facile.
Pour compléter, je vous invite à regarder cet l’excellent talk de Kevlin Henney qui m’a beaucoup inspiré :
Prochains billets pour trolls : “Une tabulation, deux ou quatre espaces pour l’indentation ? “ …

Commentaires