Apache Archiva sur Raspberry PI
pour centraliser ses artefacts et autres archetypes ...

“Il me faut un repo Maven dédié !”. Voilà ce qui m’est venu en tête quand j’ai dû changer
de machine récemment alors que tous les artefacts maven que je produisais étaient capitalisés dans le .m2/repository de mon home. Autant dire “Pas capitalisés”.
Bien sûr, j’utilise un repo Nexus au boulot mais je change d’activité et je vais devenir plus mobile, il me faut donc une solution.
J’aurais pu prendre une image Docker et la déployer sur AWS ou équivalent : la solution de facilité qui demande toutefois un peu de “ressource” financière.
Et je le vois, là, rose, toutes diodes allumées, connecté à ma box, servant de proxy Squid de temps en temps. Mon Raspberry PI 1, je l’entends encore me dire “Moi je peux, moi je peux, moi je peux !” en trépignant dans son joli boitier.
Etat des lieux
En toute confiance alors, je me dis que la petite coquette boitounnette rose pourra effectivement rendre le service.

Mon Raspberry 1ère génération m’en avait déjà rendu pas mal soit par le passé, soit toujours en place :
- serveur d’applications Tomcat, GlassFish ! (si si !)
- serveur de Blog
- Console de RetroGaming avec Retropie … avec quand même quelques lenteurs pour certains émulateurs
- serveur “NextCloud”
- et donc plus récemment proxy SQUID et proxy APT.
Quand même, finalement, c’est pas mal pour un RPI1 !
J’ai aussi un RPI3, mais celui-là me sert officiellement de console retrogaming : il y a des priorités.
Donc c’est parti, je vérifie que Java 8 est bien installé dessus :
pi@raspberrypi:~ $ java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) Client VM (build 25.65-b01, mixed mode)
Parfait, en plus il s’agit de la version “Oracle” accessible par le PPA de WebUpd8Team :
S’il n’est pas installé, tout est là : https://launchpad.net/~webupd8team/+archive/ubuntu/java
Petit rappel des caractéristiques de la bête :
- Processeur ARM
- 700 Mhz (overclocké à 800 Mhz … ça me rappelle mon bouton Turbo sur mon DX2 66)
- 512 Mo RAM
pi@raspberrypi:~ $ uname -a
Linux raspberrypi 4.9.59+ #1047 Sun Oct 29 11:47:10 GMT 2017 armv6l GNU/Linux
A ce moment-là, un doute commence à apparaitre … Ca va être “léger” quand même. Tant pis, le défi m’intéresse … C’est parti !
Sonatype Nexus versus Apache Archiva

Attention, ici il ne s’agit pas de comparer ces deux solutions d’un point de vue robustesse et professionalisme, bien entendu. En outre, j’ai plus d’expérience avec Nexus et j’apprécie beaucoup cet outil. Cependant, je sais que c’est consommateur de mémoire … et c’est justement ce qui fait défaut sur mon RPI.
Je choisis donc une solution plus légère : Apache Archiva. En plus cela me fera une compétence supplémentaire à caser sur LinkedIn.
Plus légère, simplement en lisant de la documentation. Je n’ai fait aucun test, je fais donc confiance à la communauté.
Installation d’Apache Archiva
Je pars du principe que vous avez déjà un RPI qui fonctionne, avec Raspbian et que vous avez activé un accès SSH à distance. Ce n’est donc pas l’objet de ce tutorial.
On commence par faire les choses proprement en créant un utilisateur dédié et son groupe :
$ sudo adduser archiva
Puis on télécharge Apache Archiva, que l’on décompresse, et que l’on place dans /opt/archiva en y
accordant les bons droits.
$ wget http://www-eu.apache.org/dist/archiva/2.2.3/binaries/apache-archiva-2.2.3-bin.tar.gz
$ tar -xvf apache-archiva-2.2.3-bin.tar.gz
$ sudo mv apache-archiva-2.2.3 /opt/archiva
$ sudo chown -R archiva:archiva /opt/archiva
La confiance règne alors, je bascule sous le compte “archiva” pour lancer le script de démarrage.
$ su archiva
$ cd /opt/archiva/bin
$ ./archiva
et bim ! Ca ne marche pas !
Unable to locate any of the following operational binaries:
/opt/archiva2/bin/./wrapper-linux-armv6l-64
/opt/archiva2/bin/./wrapper-linux-armv6l-32
/opt/archiva2/bin/./wrapper

Et oui le lanceur archiva n’est pas un simple java -jar. Il utilise un wrapper qui monte tout un environnement et un paramétrage spécifique. Pour en savoir plus sur ce wrapper : https://wrapper.tanukisoftware.com/doc/english/download.jsp
Recompilation du Java Wrapper pour Raspberry PI
Il me faut donc récupérer le source du wrapper, le recompiler pour ARM (armv6l-32) et placer les fichiers dans le répertoire d’archiva. Attention au passage les build pour ARM7 ne fonctionne pas sur RPI. Il faut donc bien recompiler l’ensemble pour le RPI.
On télécharge les sources du Wrapper :
$ wget -O wrapper-sources.zip https://sourceforge.net/projects/wrapper/files/wrapper_src/Wrapper_3.5.35_20180412/wrapper_3.5.35_src.zip/download
$ unzip wrapper-sources.zip
Pour recompiler il faudra aussi “ant” et exporter JAVA_HOME s’il n’est pas défini :
$ su
$ apt get install ant
$ exit
$ export JAVA_HOME=/usr/lib/jvm/jdk-8-oracle-arm32-vfp-hflt
$ export ANT_HOME=/usr/share/ant
Il est temps de lancer la compilation du Wrapper :
$ cd wrapper_3.5.35_src
$ chmod +x ./build32.sh
$ ./build32.sh
Ce qui donne, au bout de 5 min et 30 secondes (!!)
--------------------
Wrapper Build System
using /home/archiva/wrapper_3.5.35_src/./build.xml
--------------------
Buildfile: /home/archiva/wrapper_3.5.35_src/build.xml
...
... (coupé, car trop long)
...
main:
BUILD SUCCESSFUL
Total time: 5 minutes 30 seconds
Maintenant que le build s’est bien déroulé, il faut copier les fichiers dans les bons répertoires d’archiva.
$ cp bin/wrapper /opt/archiva/bin/wrapper-linux-armv6l-32
$ cp lib/wrapper.jar /opt/archiva/lib
$ cp lib/libwrapper.so /opt/archiva/lib/libwrapper-linux-armhf-32.so
On change un peu le paramétrage du wrapper, en ce qui concerne l’usage mémoire :
$ nano /opt/archiva/conf/wrapper.conf
et on change les paramètres suivants :
wrapper.java.initmemory=64
wrapper.java.maxmemory=128
Et enfin on vérifie le lancement en mode console :
$ /opt/archiva/bin/archiva console
Ce qui donne :
Running Apache Archiva...
wrapper | --> Wrapper Started as Console
wrapper | Java Service Wrapper Community Edition 32-bit 3.5.35
wrapper | Copyright (C) 1999-2018 Tanuki Software, Ltd. All Rights Reserved.
wrapper | http://wrapper.tanukisoftware.com
wrapper |
wrapper | Launching a JVM...
jvm 1 | Java HotSpot(TM) Client VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
jvm 1 | WrapperManager: Initializing...
jvm 1 | 2018-04-13 17:22:44.531:WARN:oejd.ContextDeployer:ContextDeployer is deprecated. Use ContextProvider
jvm 1 | 2018-04-13 17:22:44.598:WARN:oejd.WebAppDeployer:WebAppDeployer is deprecated. Use WebAppProvider
jvm 1 | 2018-04-13 17:22:45.661:INFO:oejs.Server:jetty-8.1.14.v20131031
jvm 1 | 2018-04-13 17:22:45.889:INFO:oejs.NCSARequestLog:Opened /opt/archiva/logs/request-20180413.log
jvm 1 | 2018-04-13 17:22:46.441:INFO:oejd.ContextDeployer:Deploy /opt/archiva/contexts/archiva.xml -> o.e.j.w.WebAppContext{/,null},/opt/archiva/apps/archiva
...
...
Et voilà, au bout de 9 minutes sur mon RPI overclocké, Apache Archiva est fonctionnel.
C’est le moment d’aller prendre un premier café en récompense …
Configuration d’Apache Archiva
Je le configure avec un compte admin et un compte fxjavadevblog qui pourra publier des artefacts
dans archiva.internal et archiva.snapshots. Ce point est assez intuitif par l’interface web de Archiva,
donc pas besoin de le détailler. Même un administrateur Windows pourrait y arriver.
Il ne manque plus que de faire en sorte qu’Archiva soit lancé au démarrage du RPI, si jamais le RPI reboote.
Au préalable, il faut modifier le script bin/archiva au préalable pour y ajouter (en décommentant) la ligne suivante :
RUN_AS_USER=archiva
J’ajoute aussi en entête de ce fichier les “Run Levels” pour son inscription en tant que service activé et automatique :
#! /bin/sh
### BEGIN INIT INFO
# Provides: archiva
# Required-Start:
# Required-Stop:
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Apache Archiva Repo
# Description: Apache Archiva Maven Repository
### END INIT INFO
Enfin :
- je fais un lien sur le script,
- je l’enregistre comme daemon de démarrage,
- je l’active,
- je le lance,
- je vérifie qu’il fonctionne.
$ su
$ ln -s /opt/archiva/bin/archiva /etc/init.d/archiva
$ update-rc.d archiva defaults
$ sysctl enable archiva
$ sysctl start archiva
$ sysctl status archiva
J’obtiens ceci :
$ systemctl status archiva
● archiva.service - LSB: Apache Archiva Repo
Loaded: loaded (/etc/init.d/archiva; generated; vendor preset: enabled)
Active: active (exited) since Fri 2018-04-13 22:06:47 CEST; 10min ago
Docs: man:systemd-sysv-generator(8)
CGroup: /system.slice/archiva.service
avril 13 22:06:44 raspberrypi systemd[1]: Starting SYSV: Apache Archiva...
avril 13 22:06:45 raspberrypi su[952]: Successful su for archiva by root
avril 13 22:06:45 raspberrypi su[952]: + ??? root:archiva
avril 13 22:06:45 raspberrypi su[952]: pam_unix(su:session): session opened for user archiva by (uid=0)
avril 13 22:06:46 raspberrypi archiva[871]: Starting Apache Archiva...
avril 13 22:06:47 raspberrypi archiva[871]: Removed stale pid file: /opt/archiva/logs/archiva.pid
avril 13 22:06:47 raspberrypi systemd[1]: Started SYSV: Apache Archiva.
Victoire, tout va bien.

C’est le moment d’aller prendre un second petit café en récompense …
Configuration de ~/.m2/settings.xml
Il faut maintenant modifier le fichier ~/.m2/settings.xml de la station pour le prendre en compte.
Attention ici, raspberry est un alias DNS que j’ai placé dans mon fichier /etc/hosts.
Plus simplement, vous pourrez le remplacer par une adresse IP, éventuellement.
De plus je fais donc en sorte qu’Archiva soit mon proxy pour tous les artefacts issus de Maven Central.
Cette déclaration se fait dans la partie <mirror> ... </mirror>
<mirrors>
<mirror>
<id>archiva.default</id>
<url>http://raspberry:8080/repository/internal/</url>
<mirrorOf>external:*</mirrorOf>
</mirror>
</mirrors>
<servers>
<server>
<id>archiva.internal</id>
<username>fxjavadevblog</username>
<password>xxxxxxxx</password>
</server>
<server>
<id>archiva.snapshots</id>
<username>fxjavadevblog</username>
<password>xxxxxxxx</password>
</server>
</servers>
Configuration des “pom.xml”
Bien sûr, je n’oublie pas de modifier les POM de mes projets Java, car ce sera le “goal” install de maven qui ira publier les artefacts. D’ailleurs sur ce point, la documentation officielle d’Apache Archiva est fausse, car les URL de publication sont éronnées.
Voici une configuration correcte :
<distributionManagement>
<repository>
<id>archiva.internal</id>
<name>Internal Release Repository</name>
<url>http://raspberry:8080/repository/internal/</url>
</repository>
<snapshotRepository>
<id>archiva.snapshots</id>
<name>Internal Snapshot Repository</name>
<url>http://raspberry:8080/repository/snapshots/</url>
</snapshotRepository>
</distributionManagement>
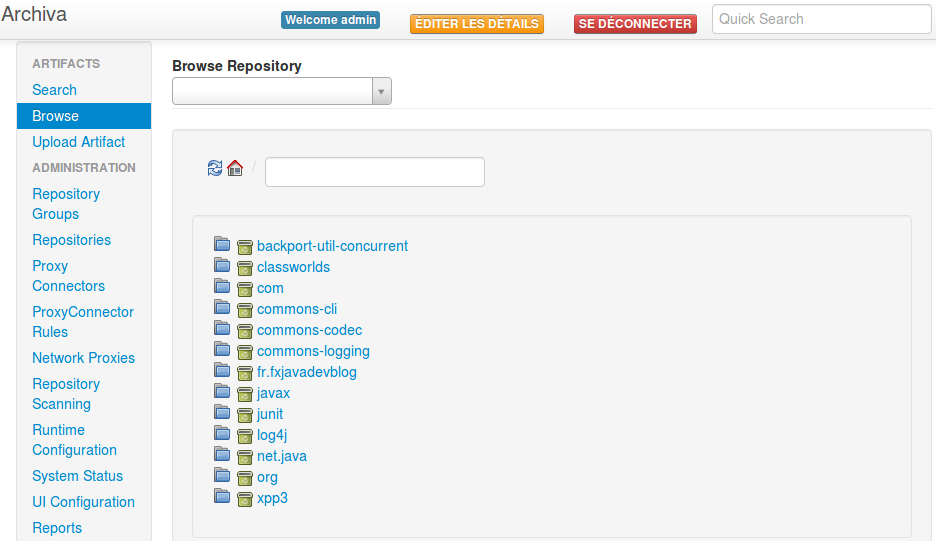
et après publication de mon projet, tout est bien présent dans Archiva dans fr.fxjavadevblog. On y voit aussi les autres artefacts téléchargés depuis Maven Central.
Conclusion
J’adore quand un plan se déroule sans accroc …
Pour achever le tout, il me faudra activer une redirection de port sur la BOX pour pouvoir y accéder quand je suis en déplacement ou, mieux, un VPN (mais cela dépasse le cadre de ce petit tuto) et le tour sera joué …
Encore un truc qui devait prendre 15 minutes …

Commentaires